We know that JavaScript SEO is becoming more of an interest area as Google gets better at rendering content served in this way. However, this presents a high resource demand on Google and many still believe that there are adverse implications on how quickly content is indexed compared to content rendered in the source itself.
To investigate this further we devised a short test to see how the speed of indexing differs when content is rendered in and out of JavaScript.
TL;DR
Whilst a relatively small study, for the time-poor/less patient, here are the top five key takeaways:
- JavaScript implemented content appears to be crawled & indexed in the same time as content loaded in the source; assuming optimal conditions.
- JavaScript content is much more unpredictable and there are other elements, which could cause content to be dropped or not indexed.
- Mixed content issues can stop Google indexing JavaScript content altogether.
- JavaScript content presents a more viable option for deploying content than we’d initially thought.
- This test needs to be run under many different conditions (and many more times) for these findings to be really exhaustative.
If you are only going to read to here – please skip onto the “limitations” below to at least understand where the gaps are here. Whilst we’re confident we can ask some pretty worthwhile questions off the back of the study, it would be a bit premature to come to any solid conclusions at this stage.
How compatible is JavaScript with SEO?
In August last year, I read a blog that changed a fairly hefty chunk of how I thought about SEO. There’s a chance you’ll have seen this, “JavaScript and SEO: The Difference Between Crawling and Indexing” by Barry Adams, as it picked up a lot of attention when it was published. In it Barry may have provided one of the most succinct and well-formed ways of thinking about JavaScript and the impact on SEO I’ve ever read. In a nutshell, JavaScript can work for SEO, but you’re making things more difficult for yourself by using it – avoid if possible.
Whilst it is becoming a hot topic today, JavaScript and SEO have, for a long time, been antagonists. I remember the days of validating indexable content on the page by using Lynx browser (as a proxy for Google’s own rendering ability) to show me what we thought Google could “see” – JavaScript didn’t fare well here!
But since Google has more recently stated that they render content based on (something similar to) Chrome 41, it has caused many to decree that JavaScript is ‘okay’ now.
Even if you ignore for a moment that Chrome 41 is old (in web terms, launched in 2015) and is still lagging behind many new ways of building websites, the assertion that we could leave Google to it still seems premature. This is where Barry’s blog resonated with me, the reasons I felt uncomfortable with relying on JavaScript for content were crystalised and laid-bare for everyone to see.
So we’re still off JavaScript, right? Maybe not just yet.
Something which stuck out to me on re-reading the blog back in January got me thinking, “with such JavaScript-based websites, crawling and indexing becomes slow and inefficient.”
Seems logical, believable even – a great reason to avoid JavaScript. Except, how do we know what impact this will actually have on our websites? It is hard to know, but we do have a way of testing one part of this – the speed of indexing against content rendered in the source.
If you were relying on weekly, or daily rank tracking – the “norm” – testing the speed element here may prove challenging because of the inaccuracy – give or take a day here isn’t quite good enough! However, since recently building a UI for our experimental hourly tracking (more below), it seemed like a great opportunity to see if we could get a more accurate measure of how different it may be.
Should we avoid JavaScript because it’s going to be too slow hitting SERPs? Good question, let’s see if we can get any closer to answering this.
More on Hourly Rank Tracking
We have been running this test off the back of hourly rank tracking, something that my colleague Simon and I have been working on and off for nearly a year now. It is pretty much as the name suggests, and has been developed more as an experiment – we’re starting to realise some of the potential behind this frequency of tracking results now and are opening it up to a very limited number of people – you can read more about it here.
The Process
Let us keep things simple, we’re testing for one thing – the difference in time taken for Google to index content rendered in JavaScript against content rendered in the source.
To do this should be straightforward:
- Create two identical new pages
- Each containing 250-300 words of unique copy, 1x H1, 1x <h2> + optimised title
- Page #1 has the content in the source – visible on page load
- Page #2 has the content added via Javascript – no presence in the source (including title)
- Both pages published (but orphaned from main navigation) at the same time
- Both pages fetched and rendered by Googlebot (and crawl requested) at the same time
- Monitor both keywords hourly and observe the time-difference between the two
This process needs to be repeated for each of the sites in question, we’ve picked three domains which we own, are ‘clean’ of legacy SEO and – most importantly – would not cause a problem if the test went wrong.
Here are they ran through Majestic:
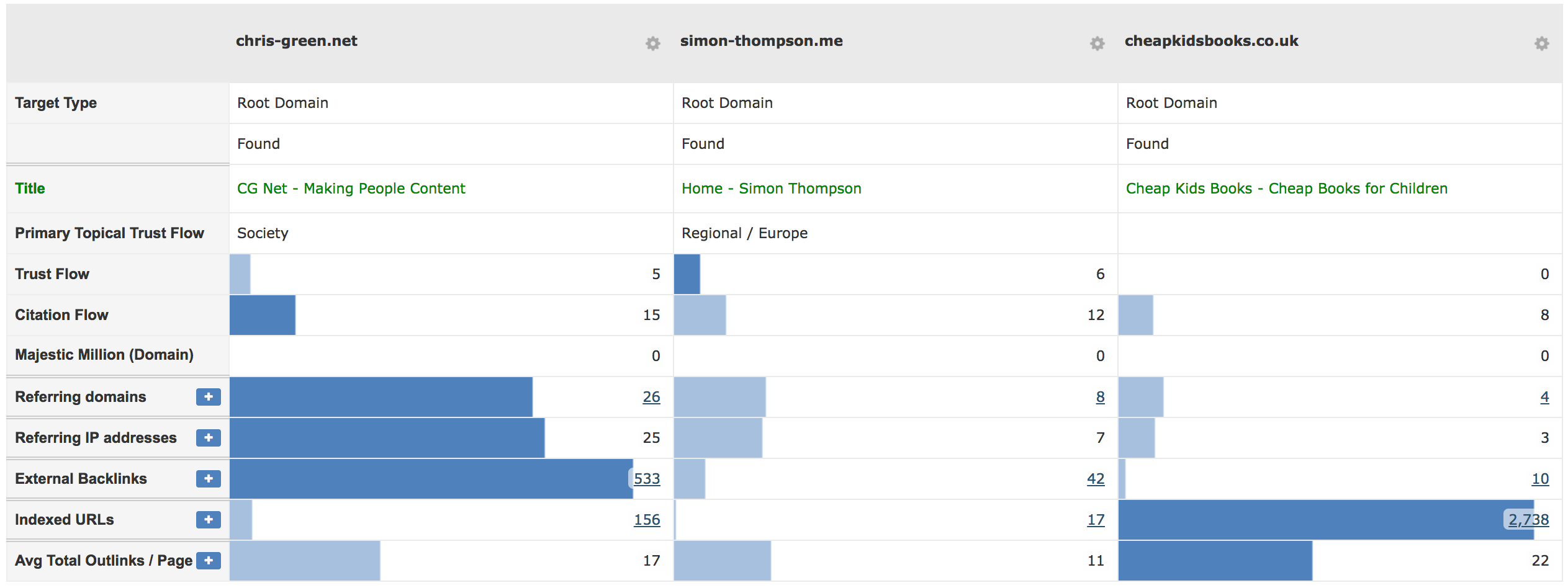
Again, to make the test “fair,” all the following were common through each:
- All WordPress
- All low-authority
- JavaScript content implemented via Google Tag Manager
- Fictional content/keywords – selected because of no exact match results
Javascript Content
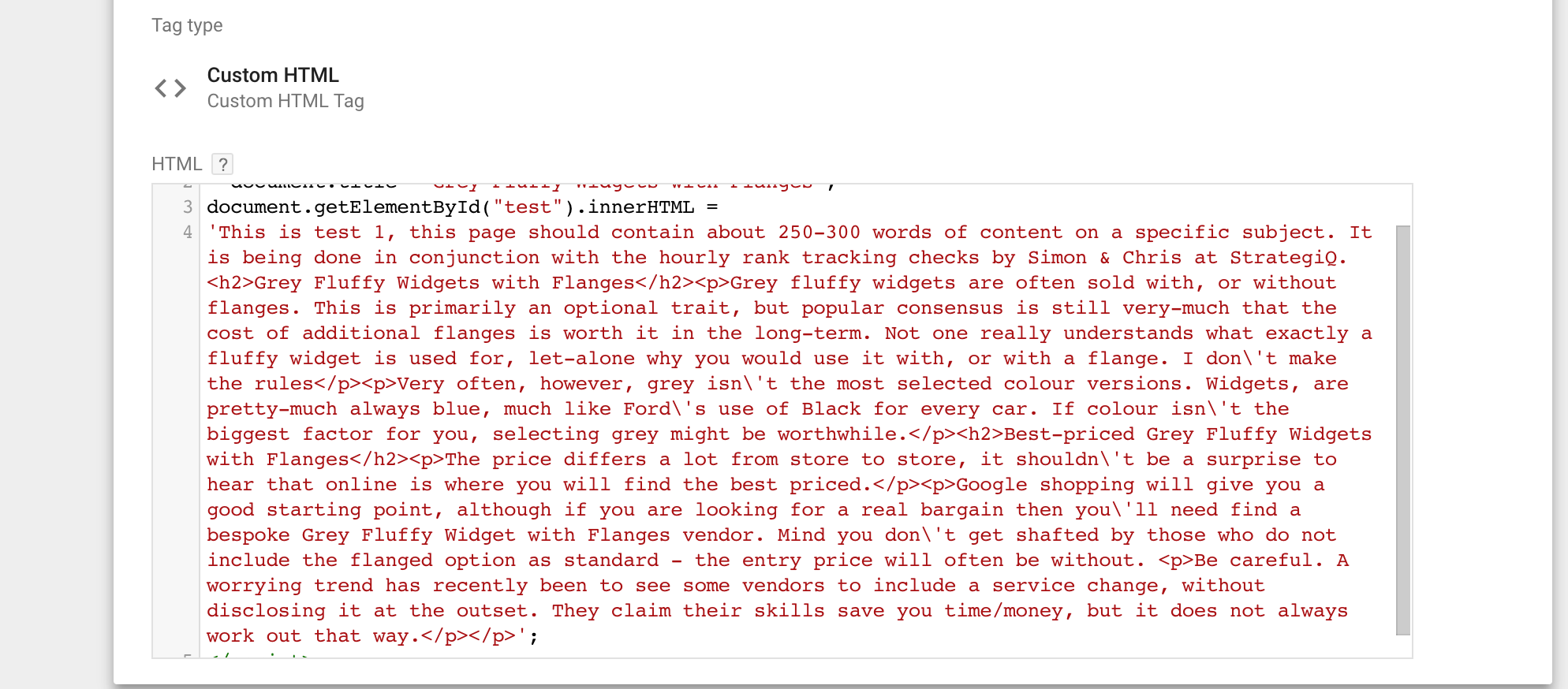
Google Tag Manager felt like a logical choice for deploying the JavaScript on the test pages. If nothing else, because more and more people have started to use it for this purpose, we felt it would be easy to relate to.
Below is the tag we used to implement the content (triggered on the test page only):
When you check the source itself, you only see the “noscript” message I introduced – i.e. if you see this, JavaScript isn’t working. Fetched through Google Search Console, all is as expected:
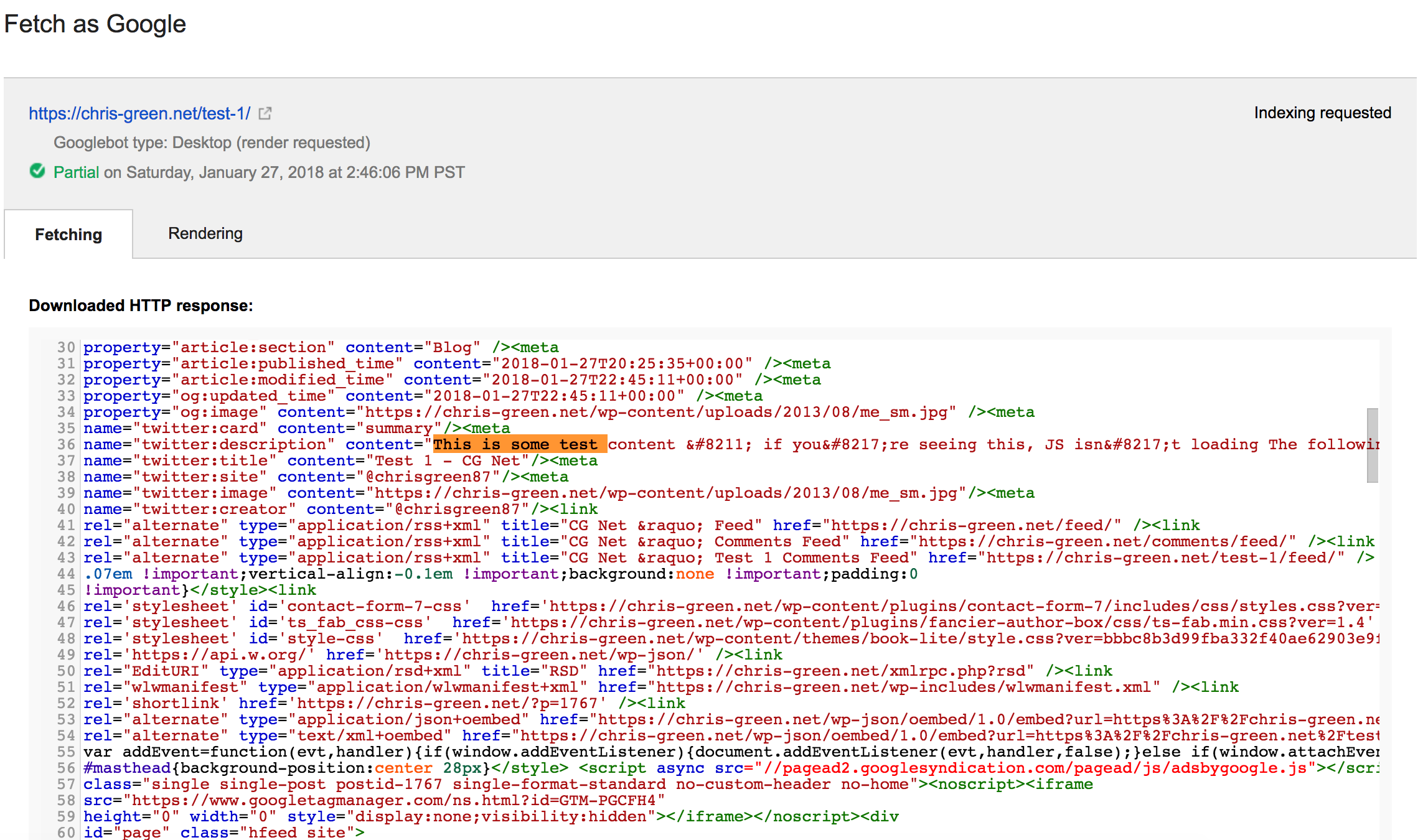
More importantly, when you trigger a fetch and render in Google Search Console; what Googlebot sees and what the user see are identical – the JavaScript content loads in.

We ran through this process with all six of the pages (three tests – three controls across three domains).
NB: The tests on each site were ran at the same time (i.e. JavaScript, non-JavaScript content), however, each site test was ran with a few weeks in between.
Results
It’s easier if we review each test result by the domain we tested it on. If nothing else, it will help highlight how each one reacted differently.
Domain 1
Control: content was indexed within the hour of it being fetched and rendered. Note the 8th – 11th of February; the server, which runs the tracking (half) restarted which meant we lost data across the board across everything during that time.
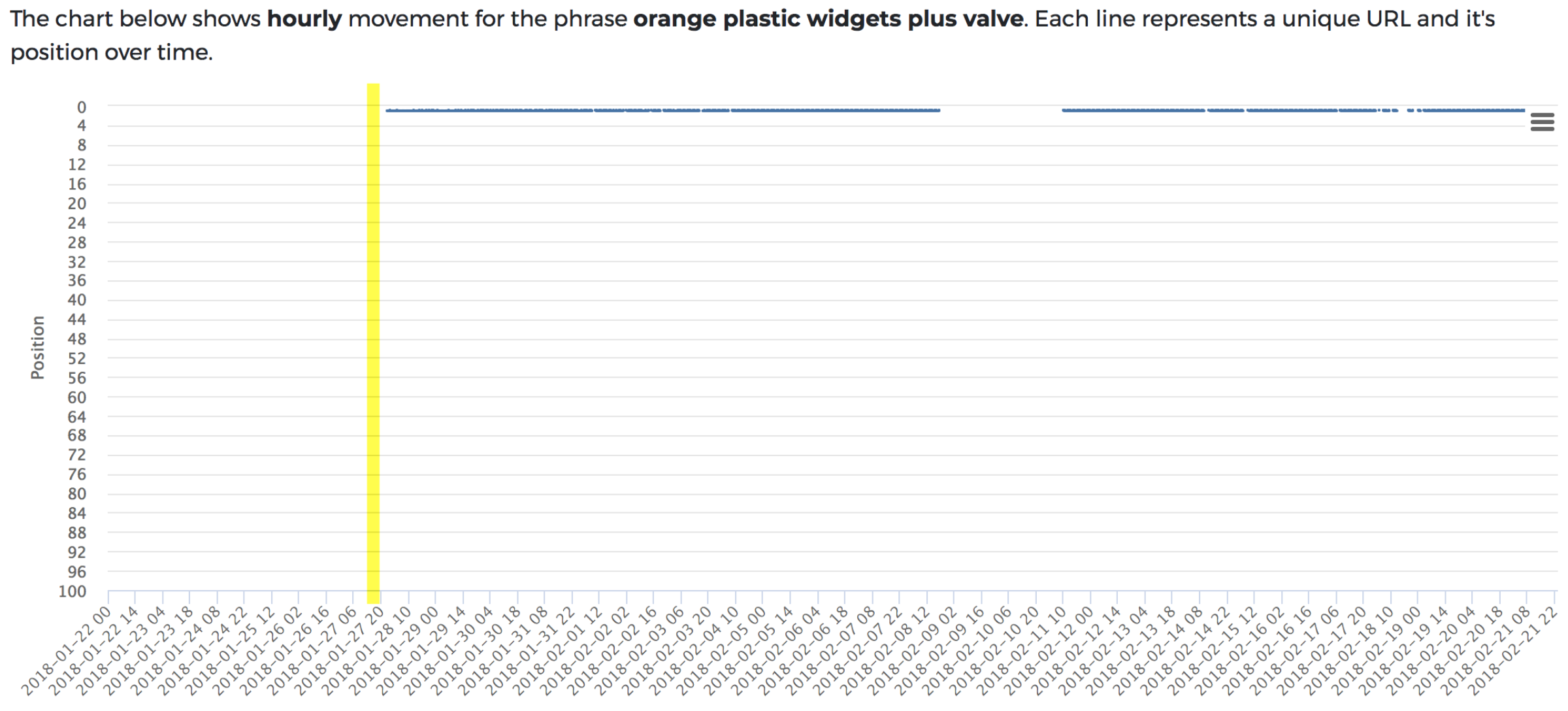
JavaScript test : No sign of the page/content ranking for two weeks following the initial fetch and render request.
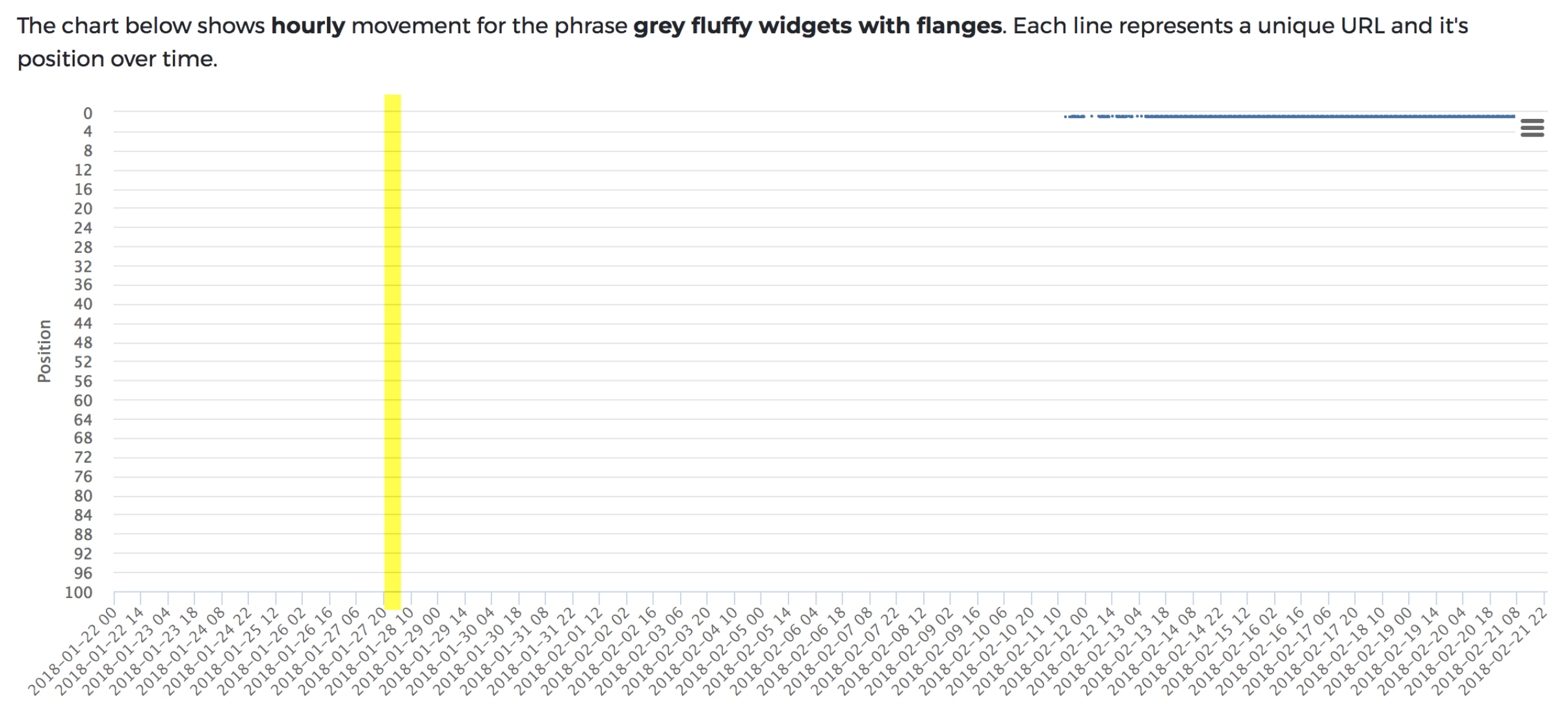
This seemed like a far bigger time-delay than we’d have imagined – two weeks! Yet, something seemed wrong. On further inspection (thanks to Kieran of The Web Shed), there was a mixed content error on the page (rookie mistake!), which was brought about by a WordPress plugin that needed updating.
As soon as I fixed the error, I ran another indexing request and the page was ranked within the hour (second line below).
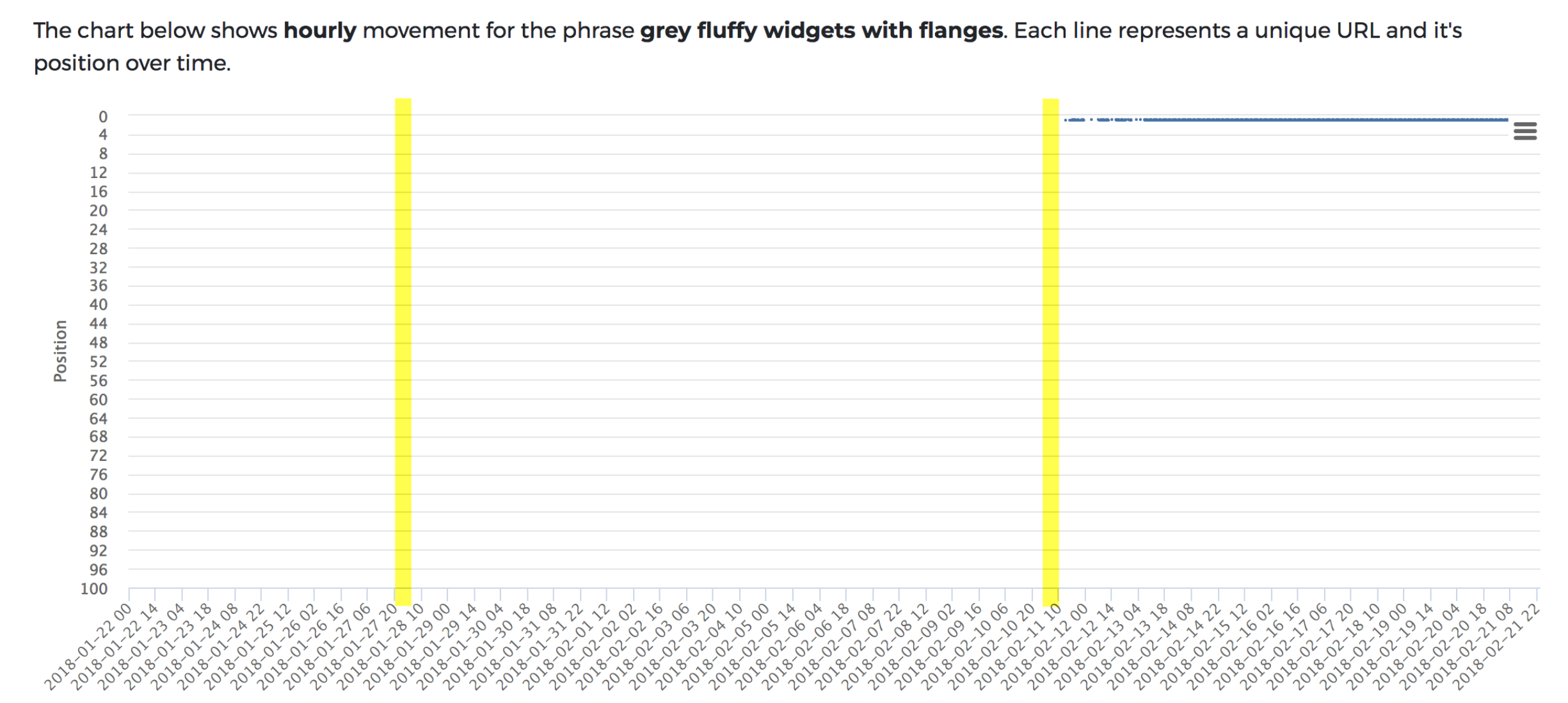
So, in this instance, the unsafe scripts appeared to have stopped Google from indexing the content. As soon as we fixed the error, it was indexed.
As a further test, I have re-created the error to see if Google would take issue with JavaScript content with unsafe scripts after the content was indexed. The question here was, “if an insecure content error could cause content to drop out again?” In short, no, it doesn’t seem to impact rankings after the event.
Domain 2
Control: As per the first test, the content was indexed within the hour.
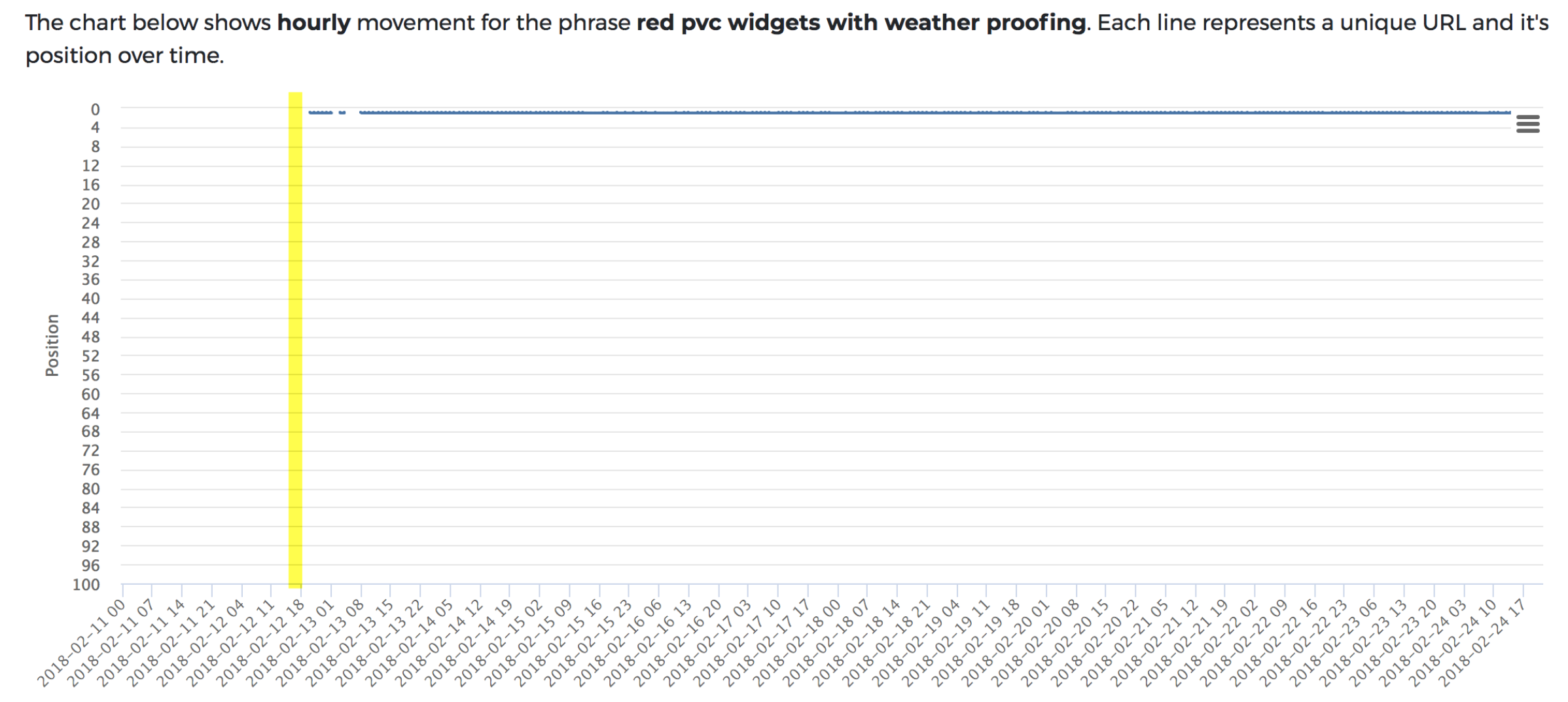
JavaScript test: Like test one (when the errors were fixed), the content was indexed within the hour. Except, there’s a drop shortly afterwards.
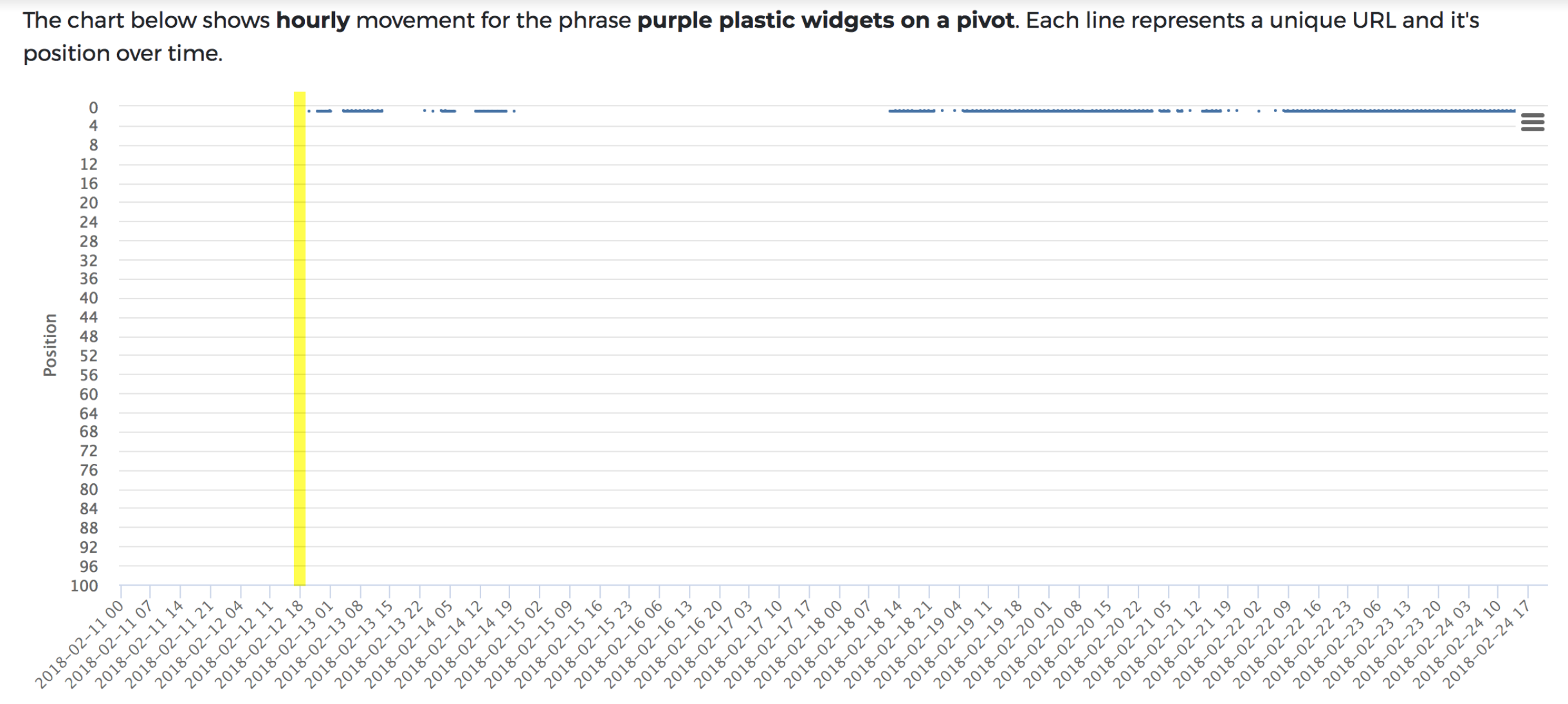
Ignoring the fact that rankings do seem more intermittent than the control (more on this shortly), on the 14th of February, Google dropped the ranking page with JavaScript content altogether. On closer inspection, there was no reason for this to have happened, no errors, broken content; nothing that we could see.
With another indexing request, the content was picked up again and also within the hour.

In this test, we saw a seemingly random loss of rankings for the JavaScript content whereas – Google dropped it, just like that.
It is still ranking now and we’ve not been able to recreate this.
Domain 3
Control: As per the first two tests, the content was indexed within the hour.
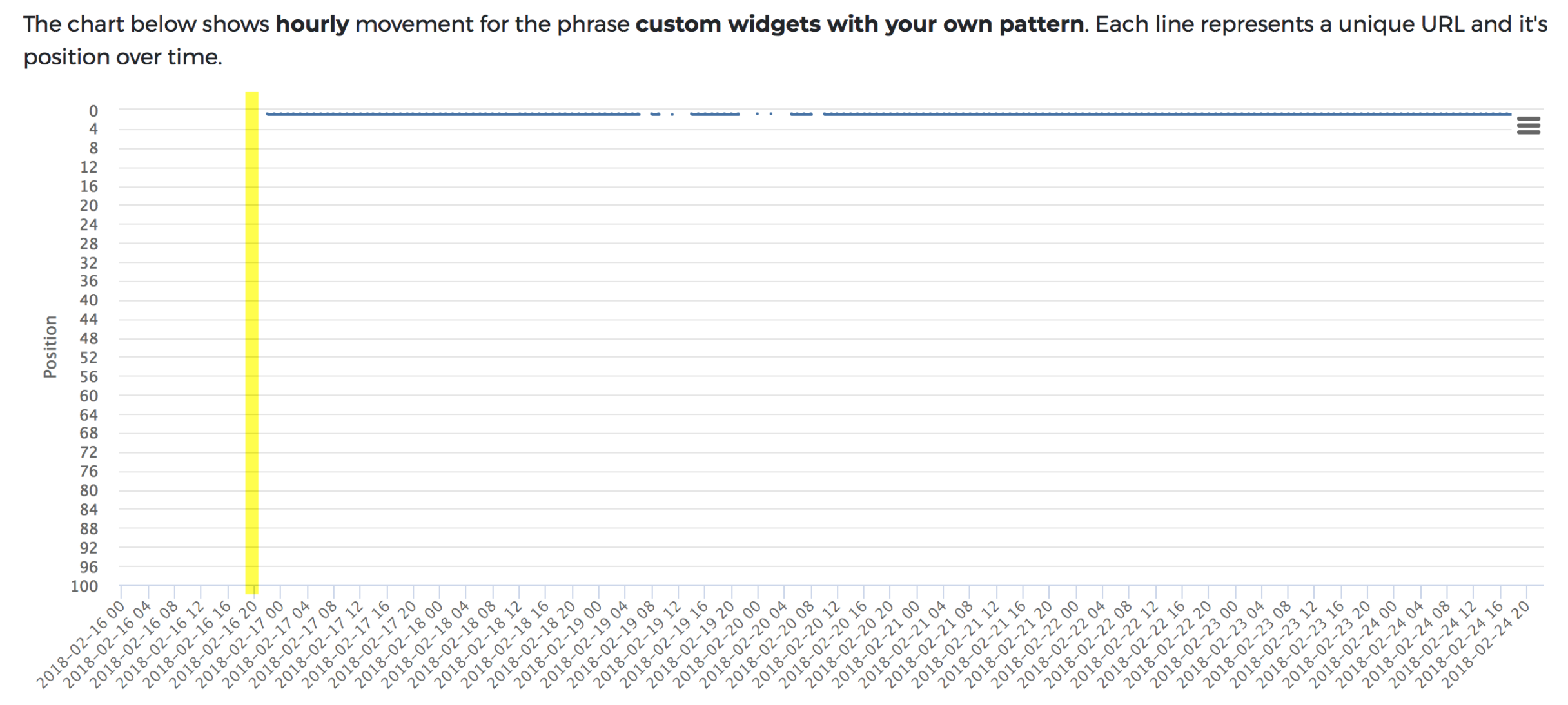
JavaScript test: Everything was indexed within the same speed as the non-JavaScript version, without any other signs of issue.
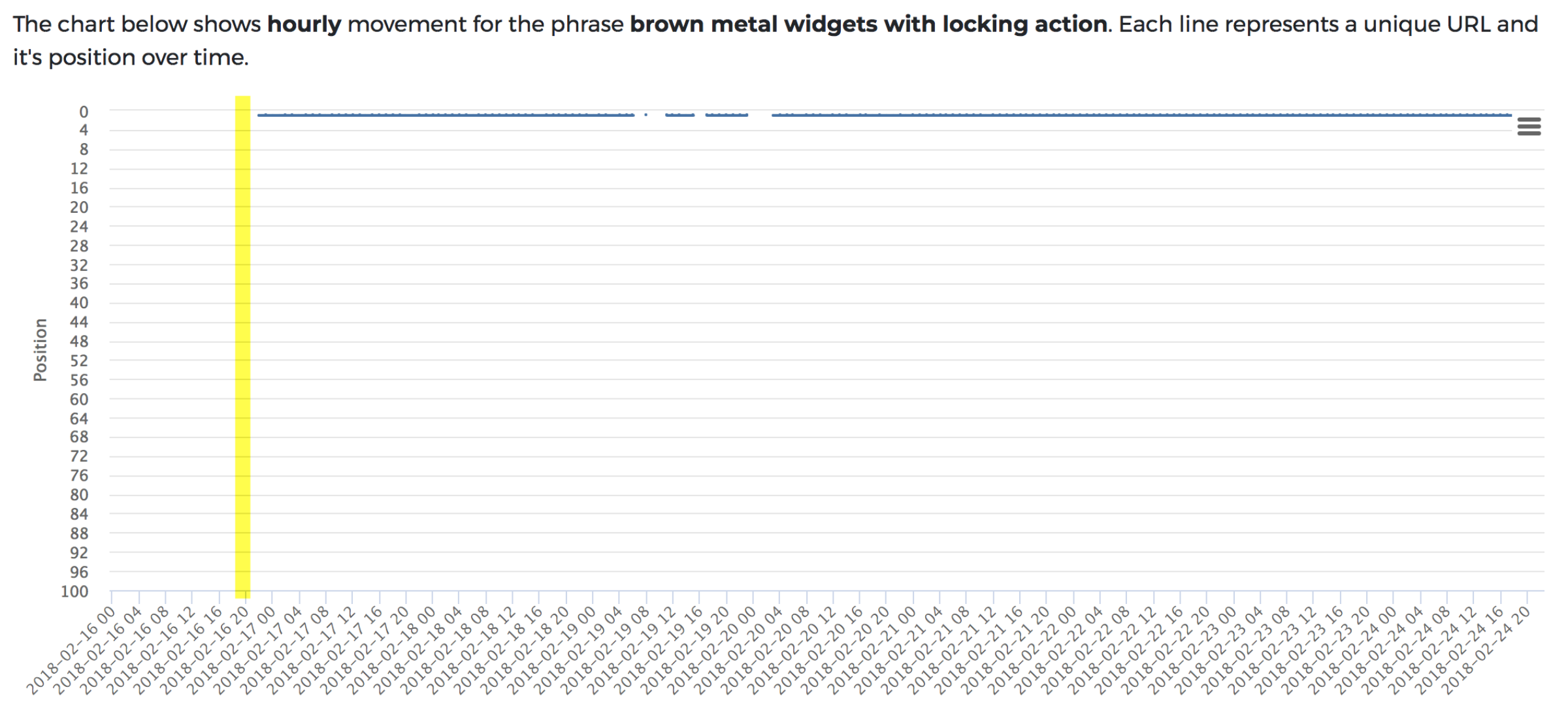
In this final test it seems that JavaScript content was crawled, indexed and ranked within the hour, just as the non-JavaScript version was.
Conclusions
Forming any far-reaching conclusions here is going to be difficult, as in all three tests the JavaScript content behaved differently. But what we can say:
- Assuming there are no errors, the JavaScript content was ranking in the same time as non-JavaScript content. JavaScript content appears to be no slower than content rendered in the source.
- Mixed content errors can stop Google from indexing JavaScript content. Whether this means it isn’t rendered by the WRS or not, we don’t know.
- JavaScript content can be dropped, seemingly at random. Although, we have only seen this in one out of the three tests and have not been able to replicate.
- When JavaScript content does rank, we saw it more likely to drop in/out of search on an hour-by-hour basis (and then come back) than the control. This could just be intermittent gaps in the data – as you see with all rank tracking – but it does happen more frequently on the JavaScript test pages. It is too soon to jump to conclusions, but it still supports the idea that JavaScript content is less reliable to rank with than content in the source.
If we look at these against the original question, “how much slower is JavaScript content to index?the early signs are that it is no slower. This is surprising to us, but as a theory, could certainly do with some more testing to validate.
What is perhaps more interesting, is what makes this process unpredictable. I am more willing to entertain the idea of JavaScript content for my sites (pending further testing), however, if a third party extension could throw up an error which could stop content being indexed, that’s a major worry. Equally, the prospect of content dropping randomly is not a welcome one.
Limitations
The main limitation here is that the study itself has been very small in size and there’s a lot we haven’t tested for.
This has been the intention in some respects – we’ve wanted to control for as many variables as we can (a difficult task in SEO!), but it does mean we need to be careful with how sweeping we are with the findings.
For final reference, here are some other limitations of the study we’ve identified which we want to outline – in the event anyone else wants to plug some gaps.
- All test sites were WordPress, but other platforms could introduce further variables, which could change the results. Ecommerce sites with crawl budget issues may find these reliability challenges are even worse.
- All sites used are relatively low in TrustFlow/CitationFlow, although we haven’t tested for how authority may impact this (if at all).
- We have only tested for how quickly the content was indexed for 0 search volume terms. Whether or not JavaScript content holds as much authority/effectiveness in more competitive niches isn’t covered.
- GTM was used as a deployment method, but there are many different ways of doing this; some potentially more stable, others far less.
- Requesting indexing via Google Search Console is convenient for testing, but is likely a poor proxy for crawling/indexing “in the wild”, undoubtedly an area we need to test more thoroughly.
What Next?
We need to test further to duplicate the results above across more different websites/ scenarios. What we could do with is more people participating or running their own versions of this – ultimately to try and disprove what we’ve said here. Anyone who is inclined to do so, contact me on Twitter, you don’t need to user hourly to run the testing, but you can always register your interest here if you want to be let onto the platform soon.
Please let me know your thoughts; do you see any glaring flaws in our methodology, want to debate any findings, or have some ideas for next time? Twitter’s best to catch me on, otherwise email also suits me, chris ‘at’ strategiq.co